Facebook built Haystack, an object storage system designed for storing photos on a large scale. The platform stores over 260 billion images which amounts to over 20 petabytes of data. One billion new photos are uploaded each week which is approx—60 terabytes of data. At peak, the platform serves over one million images per second.
Let’s understand the retired Facebook’s NAS (Network-attached storage) over NFS (Network file system) based photo storage architecture and the issues that triggered the need for the new object storage system (Haystack).
Sequence of events:
The browser sends a request to the Facebook web server for a particular photo.
The web server constructs a url for the photo and directs the browser to a CDN. If it’s a cache hit, CDN returns the photo.
If not, CDN sends the request to the photo servers. The photo servers process the request containing the url. They mount all the volumes exported by these NAS appliances over NFS. They fetch the photo from the NAS storage over NFS (Network File System).
The photo is returned to the CDN. CDN caches the photo and forwards it to the browser.
For each photo uploaded, Facebook generates and stores four images of different sizes. Photos and the associated metadata lookups in NAS caused excessive disk operations almost upto ten just for retrieving a single image.
The engineering team reduced the disk operations from ten to three by reducing the directory size of NFS volume from thousands of files per directory to hundreds.
Fetching a photo from the storage comprised of multiple steps:

If you need to understand inode, file handle and how network operations work in a distributed file system. This article on network file system discusses the concept in detail.
In the NAS system, reading the metadata from the disk was a bottleneck.
Most of the photo metadata went unread and consumed significant storage capacity. Also, the metadata was fetched from the disk into the main memory. For fetching photos at a scale of billions, this became a throughput bottleneck. This limited the number of reads that could be performed on a disk in a stipulated time.
Two issues with this:
Storing so much data on a CDN is not cost-effective.
CDN would only serve the recently uploaded and frequently accessed data. When it comes to user photos on a social network, there is a significant number of long-tail (less popular photos) requests. All the long-tail requests miss the CDN.
All the long-tail requests miss the CDN.
Haystack was designed with some key things in mind:
Keeping the disk operations for fetching a photo to at most one per read and reducing the photo metadata significantly enabling it to load in the main memory made Haystack a low latency and high throughput storage system.
Loading the metadata into the main memory significantly reduced the disk I/O operations providing 4x more reads per second than the NAS-based setup.
Haystack is made fault-tolerant and highly available by replicating photos across data centers in distinct geographical locations.
Learn to design distributed systems
Learn to design distributed systems from Educative.io, check out the below courses:
Distributed Systems for Practitioners
Grokking the Advanced System Design Interview
Scalability & System Design for Developers
Educative. io is a platform that helps software developers level up on in-demand technologies & prepare for their interviews via interactive text-based courses with embedded coding environments. They have over 975,000 learners on their platform.
io is a platform that helps software developers level up on in-demand technologies & prepare for their interviews via interactive text-based courses with embedded coding environments. They have over 975,000 learners on their platform.
The links are affiliate links. If you buy the course or a subscription, I get a cut without you paying anything extra.
In this photo storage design, the popular images are served from the CDN and the long tail photos are handled by Haystack.
The Haystack architecture consists of 3 core components:
the Haystack Store, Directory and the Cache.
When a user requests a photo, the browser requests the webserver. The webserver takes the help of the Haystack Directory to create the photo URL.
The Haystack Directory, besides creating the URL, maps logical volumes to the physical volumes. The web server uses this mapping to create the photo URLs. This mapping also comes in handy when uploading photos.
The other functions of the directory are:
Load balancing writes across logical volumes and reads across physical volumes.
Determining if a request for a photo is to be handled by the Haystack cache or the CDN.
Identifying logical volumes that have become read-only either because of operational reasons or having reached their storage capacity.
The photo request is then routed to the CDN. If the CDN misses it, the request moves forward to the Haystack Cache.
The cache is a distributed hash table that uses photo id as a key to locate the data. If the cache doesn’t hold the photo, it fetches it from the store and returns it either to the CDN or the user’s browser.
The cache is primarily used to intercept the requests for the write-enabled Haystack store machines. Because as soon as a photo is uploaded, there is a read request for it. And the file systems of the photo storage workload perform better when doing either reads or writes but not both. The cache intercepts all the read requests for the write-enabled store machines improving the throughput. For this reason, the photos after upload on a write-enabled store are pro-actively pushed to the cache.
The cache intercepts all the read requests for the write-enabled store machines improving the throughput. For this reason, the photos after upload on a write-enabled store are pro-actively pushed to the cache.
The read and write requests to the Haystack Store machines are balanced by the Haystack Directory. The Store is the persistent storage system for the photos.
The read requests to the store hold information such as photo id for a certain logical volume and from a certain physical volume. If the store doesn’t find the photo, it returns an error.
To locate a photo, the store machine only needs the photo id and the logical volume id.
A store machine manages multiple physical volumes, each containing millions of photos. Each physical volume is of the size of 100s of GBs mapped to a logical volume.
The store’s storage capacity is organized by physical volumes. For instance, a 10 terabyte storage capacity server would consist of 100 physical volumes, each having 100 GBs of storage.
The physical volumes on different machines are further grouped into logical volumes. When a photo is stored on a logical volume, it is written to all the physical volumes corresponding to that logical volume.
This redundancy averts data loss in case of hard drive and other hardware failures.
Developer Roadmap
If you are a developer and find it hard to cope with constant changes in technology. You are sick and tired of it. You are looking for ways to jump off that endless upskilling treadmill staying relevant and hireable.
You might want to check out my ebook, DEVELOPER’S ROADMAP TO EXCELLENCE AND BUILDING YOUR OWN THING, where I share with you the roadmap and techniques that I follow to keep my sanity in this ever-changing world of software development without killing myself. In it, you’ll find actionable advice and critical points that will enable you to make informed career decisions and accelerate your career at MACH speed.
The storage system runs on commodity hardware. The primary reasons for system failure include faulty hard drives, RAID controllers, motherboards, etc.
The primary reasons for system failure include faulty hard drives, RAID controllers, motherboards, etc.
For understanding commodity hardware, clustering, the infrastructure our applications are hosted on. Check out my cloud course below.
Mastering the Fundamentals of the Cloud
If you need to understand the fundamentals of cloud computing in-depth. Check out my platform-agnostic Cloud Computing 101 course. After having spent a decade in the industry writing code, I strongly believe that every software engineer should have knowledge of cloud computing. It’s the present and the future of application development and deployment.
To ensure high availability of the system background tasks are run to detect and repair failures. Periodic checks are run to check the health of the store machines and the availability of the logical volumes.
If a problem is detected with any of the store machines, all the logical volumes on that machine are immediately marked as read-only.
The underlying failure causes are investigated manually.
Reference:
Finding a needle in Haystack: Facebook’s photo storage
If you liked the article, share it on the web. You can follow scaleyourapp.com on social media, links below, to stay notified of the new content published. I am Shivang, you can read about me here!
The Photos application is one of Facebook’s most popular features. Up to date, users have uploaded over 15 billion photos which makes Facebook the biggest photo sharing website. For each uploaded photo, Facebook generates and stores four images of different sizes, which translates to a total of 60 billion images and 1.5PB of storage. The current growth rate is 220 million new photos per week, which translates to 25TB of additional storage consumed weekly. At the peak there are 550,000 images served per second. These numbers pose a significant challenge for the Facebook photo storage infrastructure.
The old photo infrastructure consisted of several tiers:
Since each image is stored in its own file, there is an enormous amount of metadata generated on the storage tier due to the namespace directories and file inodes. The amount of metadata far exceeds the caching abilities of the NFS storage tier, resulting in multiple I/O operations per photo upload or read request. The whole photo serving infrastructure is bottlenecked on the high metadata overhead of the NFS storage tier, which is one of the reasons why Facebook relies heavily on CDNs to serve photos. Two additional optimizations were deployed in order to mitigate this problem to some degree:

The new photo infrastructure merges the photo serving tier and storage tier into one physical tier. It implements a HTTP based photo server which stores photos in a generic object store called Haystack. The main requirement for the new tier was to eliminate any unnecessary metadata overhead for photo read operations, so that each read I/O operation was only reading actual photo data (instead of filesystem metadata). Haystack can be broken down into these functional layers:
In the following sections we look closely at each of the functional layers from the bottom up.
Haystack is deployed on top of commodity storage blades. The typical hardware configuration of a 2U storage blade is:
Each storage blade provides around 10TB of usable space, configured as a RAID-6 partition managed by the hardware RAID controller. RAID-6 provides adequate redundancy and excellent read performance while keeping the storage cost down. The poor write performance is partially mitigated by the RAID controller NVRAM write-back cache. Since the reads are mostly random, the NVRAM cache is fully reserved for writes. The disk caches are disabled in order to guarantee data consistency in the event of a crash or a power loss.
RAID-6 provides adequate redundancy and excellent read performance while keeping the storage cost down. The poor write performance is partially mitigated by the RAID controller NVRAM write-back cache. Since the reads are mostly random, the NVRAM cache is fully reserved for writes. The disk caches are disabled in order to guarantee data consistency in the event of a crash or a power loss.
Haystack object stores are implemented on top of files stored in a single filesystem created on top of the 10TB volume. Photo read requests result in read() system calls at known offsets in these files, but in order to execute the reads, the filesystem must first locate the data on the actual physical volume. Each file in the filesystem is represented by a structure called an inode which contains a block map that maps the logical file offset to the physical block offset on the physical volume. For large files, the block map can be quite large depending on the type of the filesystem in use. Block based filesystems maintain mappings for each logical block, and for large files, this information will not typically fit into the cached inode and is stored in indirect address blocks instead, which must be traversed in order to read the data for a file. There can be several layers of indirection, so a single read could result in several I/Os depending on whether or not the indirect address blocks are cached. Extent based filesystems maintain mappings only for contiguous ranges of blocks (extents). A block map for a contiguous large file could consist of only one extent which would fit in the inode itself. However, if the file is severely fragmented and its blocks are not contiguous on the underlying volume, its block map can grow large as well. With extent based filesystems, fragmentation can be mitigated by aggressively allocating a large chunk of space whenever growing the physical file. Currently, the filesystem of choice is XFS, an extent based filesystem providing efficient file preallocation.
Block based filesystems maintain mappings for each logical block, and for large files, this information will not typically fit into the cached inode and is stored in indirect address blocks instead, which must be traversed in order to read the data for a file. There can be several layers of indirection, so a single read could result in several I/Os depending on whether or not the indirect address blocks are cached. Extent based filesystems maintain mappings only for contiguous ranges of blocks (extents). A block map for a contiguous large file could consist of only one extent which would fit in the inode itself. However, if the file is severely fragmented and its blocks are not contiguous on the underlying volume, its block map can grow large as well. With extent based filesystems, fragmentation can be mitigated by aggressively allocating a large chunk of space whenever growing the physical file. Currently, the filesystem of choice is XFS, an extent based filesystem providing efficient file preallocation.
Haystack is a simple log structured (append-only) object store containing needles representing the stored objects. A Haystack consists of two files – the actual haystack store file containing the needles, plus an index file. The following figure shows the layout of the haystack store file:
The first 8KB of the haystack store is occupied by the superblock. Immediately following the superblock are needles, with each needle consisting of a header, the data, and a footer:
A needle is uniquely identified by its <Offset, Key, Alternate Key, Cookie> tuple, where the offset is the needle offset in the haystack store. Haystack doesn’t put any restriction on the values of the keys, and there can be needles with duplicate keys. Following figure shows the layout of the index file:
There is a corresponding index record for each needle in the haystack store file, and the order of the needle index records must match the order of the associated needles in the haystack store file. The index file provides the minimal metadata required to locate a particular needle in the haystack store file. Loading and organizing index records into a data structure for efficient lookup is the responsibility of the Haystack application (Photo Store in our case). The index file is not critical, as it can be rebuilt from the haystack store file if required. The main purpose of the index is to allow quick loading of the needle metadata into memory without traversing the larger Haystack store file, since the index is usually less than 1% the size of the store file.
The index file provides the minimal metadata required to locate a particular needle in the haystack store file. Loading and organizing index records into a data structure for efficient lookup is the responsibility of the Haystack application (Photo Store in our case). The index file is not critical, as it can be rebuilt from the haystack store file if required. The main purpose of the index is to allow quick loading of the needle metadata into memory without traversing the larger Haystack store file, since the index is usually less than 1% the size of the store file.
A Haystack write operation synchronously appends new needles to the haystack store file. After the needles are committed to the larger Haystack store file, the corresponding index records are then written to the index file. Since the index file is not critical, the index records are written asynchronously for faster performance. The index file is also periodically flushed to the underlying storage to limit the extent of the recovery operations caused by hardware failures.![]() In the case of a crash or a sudden power loss, the haystack recovery process discards any partial needles in the store and truncates the haystack store file to the last valid needle. Next, it writes missing index records for any trailing orphan needles at the end of the haystack store file. Haystack doesn’t allow overwrite of an existing needle offset, so if a needle’s data needs to be modified, a new version of it must be written using the same <Key, Alternate Key, Cookie> tuple. Applications can then assume that among the needles with duplicate keys, the one with the largest offset is the most recent one.
In the case of a crash or a sudden power loss, the haystack recovery process discards any partial needles in the store and truncates the haystack store file to the last valid needle. Next, it writes missing index records for any trailing orphan needles at the end of the haystack store file. Haystack doesn’t allow overwrite of an existing needle offset, so if a needle’s data needs to be modified, a new version of it must be written using the same <Key, Alternate Key, Cookie> tuple. Applications can then assume that among the needles with duplicate keys, the one with the largest offset is the most recent one.
The parameters passed to the haystack read operation include the needle offset, key, alternate key, cookie and the data size. Haystack then adds the header and footer lengths to the data size and reads the whole needle from the file. The read operation succeeds only if the key, alternate key and cookie match the ones passed as arguments, if the data passes checksum validation, and if the needle has not been previously deleted (see below).
The delete operation is simple – it marks the needle in the haystack store as deleted by setting a “deleted” bit in the flags field of the needle. However, the associated index record is not modified in any way so an application could end up referencing a deleted needle. A read operation for such a needle will see the “deleted” flag and fail the operation with an appropriate error. The space of a deleted needle is not reclaimed in any way. The only way to reclaim space from deleted needles is to compact the haystack (see below).
Photo Store Server is responsible for accepting HTTP requests and translating them to the corresponding Haystack store operations. In order to minimize the number of I/Os required to retrieve photos, the server keeps an in-memory index of all photo offsets in the haystack store file. At startup, the server reads the haystack index file and populates the in-memory index. With hundreds of millions of photos per node (and the number will only grow with larger capacity drives), we need to make sure that the index will fit into the available memory. This is achieved by keeping a minimal amount of metadata in memory, just the information required to locate the images. When a user uploads a photo, it is assigned a unique 64-bit id. The photo is then scaled down to 4 different sizes. Each scaled image has the same random cookie and 64-bit key, and the logical image size (large, medium, small, thumbnail) is stored in the alternate key. The upload server then calls the photo store server to store all four images in the Haystack. The in-memory index keeps the following information for each photo: Haystack uses the open source Google sparse hash data structure to keep the in-memory index small, since it only has 2 bits of overhead per entry.
This is achieved by keeping a minimal amount of metadata in memory, just the information required to locate the images. When a user uploads a photo, it is assigned a unique 64-bit id. The photo is then scaled down to 4 different sizes. Each scaled image has the same random cookie and 64-bit key, and the logical image size (large, medium, small, thumbnail) is stored in the alternate key. The upload server then calls the photo store server to store all four images in the Haystack. The in-memory index keeps the following information for each photo: Haystack uses the open source Google sparse hash data structure to keep the in-memory index small, since it only has 2 bits of overhead per entry.
A write operation writes photos to the haystack and updates the in-memory index with the new entries. If the index already contains records with the same keys then this is a modification of existing photos and only the index records offsets are modified to reflect the location of the new images in the haystack store file. Photo store always assumes that if there are duplicate images (images with the same key) it is the one stored at a larger offset which is valid.
Photo store always assumes that if there are duplicate images (images with the same key) it is the one stored at a larger offset which is valid.
The parameters passed to a read operation include haystack id and a photo key, size and cookie. The server performs a lookup in the in-memory index based on the photo key and retrieves the offset of the needle containing the requested image. If found it calls the haystack read operation to get the image. As noted above haystack delete operation doesn’t update the haystack index file record. Therefore a freshly populated in-memory index can contain stale entries for the previously deleted photos. Read of a previously deleted photo will fail and the in-memory index is updated to reflect that by setting the offset of the particular image to zero.
After calling the haystack delete operation the in-memory index is updated by setting the image offset to zero signifying that the particular image has been deleted.
Compaction is an online operation which reclaims the space used by the deleted and duplicate needles (needles with the same key). It creates a new haystack by copying needles while skipping any duplicate or deleted entries. Once done it swaps the files and in-memory structures.
The HTTP framework we use is the simple evhttp server provided with the open source libevent library. We use multiple threads, with each thread being able to serve a single HTTP request at a time. Because our workload is mostly I/O bound, the performance of the HTTP server is not critical.
Haystack presents a generic HTTP-based object store containing needles that map to stored opaque objects. Storing photos as needles in the haystack eliminates the metadata overhead by aggregating hundreds of thousands of images in a single haystack store file. This keeps the metadata overhead very small and allows us to store each needle’s location in the store file in an in-memory index. This allows retrieval of an image’s data in a minimal number of I/O operations, eliminating all unnecessary metadata overhead.
This allows retrieval of an image’s data in a minimal number of I/O operations, eliminating all unnecessary metadata overhead.
Peter Vajgel, Doug Beaver and Jason Sobel are infrastructure engineers at Facebook.
More and more people are getting into social networks, who are rapidly filling them with content. Facebook's data warehouse has tripled in the past year, reaching 300 PB. The company's main problem is that these three hundred petabytes must remain easily accessible to a billion users. How does the largest social network cope with this task?
For Facebook employees, "big data" is a daily reality that throws up new challenges. A whole department of specialists from different fields is constantly developing promising methods of data storage. Any new system is first tested on real arrays, after which a decision is made: implement it, send it for revision, or completely change the proposed approach.
At the hardware level, Facebook uses traditional technologies such as disk storage and RAID arrays. The peculiarity is that they can be easily scaled on the fly due to the cluster platform.
The hierarchical HDFS distributed file system is used in Facebook data centers to simplify replication and synchronization processes. However, this is not a typical solution based on the Hadoop platform.
Facebook's infrastructure is based on the Hive software add-on, which uses an index system to speed up processing and provides a SQL-like HiveQL query language. Storing metadata in the DBMS significantly speeds up the execution of semantic checks when executing queries.
Before files are written to HDFS, they are pre-compressed, and the algorithm and compression settings are selected heuristically for each data block. The implementation of the Map-Reduce query processing system called Corona also has its differences. It is optimized for working with large tables.
Most relational databases organize data in two-dimensional tables that are parsed row by row. Hive uses a hybrid multi-column record format (RCFile) adapted for storing relational tables on clusters.
Hive uses a hybrid multi-column record format (RCFile) adapted for storing relational tables on clusters.
The RCFile data layout is a systematic combination of several components, including data storage format, data compression approaches, and read optimization techniques. It provides four key benefits: fast data loading, high query processing speed, efficient use of disk space, and good adaptability of dynamic data access patterns.
In the general case, the translation of tabular data into a bit sequence is performed first by rows and then by columns, but RCFile has an important optimization: table columns are written one after another in adjacent blocks and are compressed individually using the Zlib / LZO codec, supplied with a description in the form metadata.
Thanks to this approach, the read operation can be limited to performing selective unpacking of data. Therefore, when executing the query, the long steps of decompressing and deserializing unnecessary columns are skipped. Facebook experts point out that using the RCFile structure allows them to compress the original data by about five times. Without it, the company would need one and a half exabytes of storage today, and users would take a nap while waiting for the news feed to load.
Facebook experts point out that using the RCFile structure allows them to compress the original data by about five times. Without it, the company would need one and a half exabytes of storage today, and users would take a nap while waiting for the news feed to load.
With the further spread of Facebook in developing regions, the size of user profiles began to grow faster, and the Hive + RCFile bundle ceased to be a sufficiently effective solution.
The solution was found in collaboration with the Hortonworks engineering team. They developed the ORCFile format, in which the optimization of distributed data storage in the Hadoop ecosystem was further developed.
ORCFile format structure (image: facebook.com). When Hive writes tabular data with ORCFile, it is individually compressed and split into 256 MB blocks called stripes. Such an algorithm was created after numerous experiments with real databases. The stripe size of 256 MB turned out to be optimal, and the result of the work done was the conclusion about the inefficiency of using the same compression settings and constant use of the dictionary.
Facebook programmers have changed the ORCFile code so that the appropriateness of using different compression methods is determined for each data block in advance and without performance degradation. The amount of memory occupied by the dictionary was reduced by 30%, and the write speed increased by 1.4 times.
Comparison of the ORCFile format modified by Facebook with its original version and RCFile (image: facebook.com).Another important benefit of the new format is the ability to index columns and rows with their offset, eliminating the need for frequent use of delimiters.
By applying all these improvements, the Facebook team has achieved significant disk space savings. The degree of data compression was successively increased first to five times, and now to eight times. Moreover, the speed of their processing has also increased.
Today ORCFile is already successfully used to store tens of petabytes of data. Facebook's modification of ORCFile achieves an average of three times the performance of its original open source version.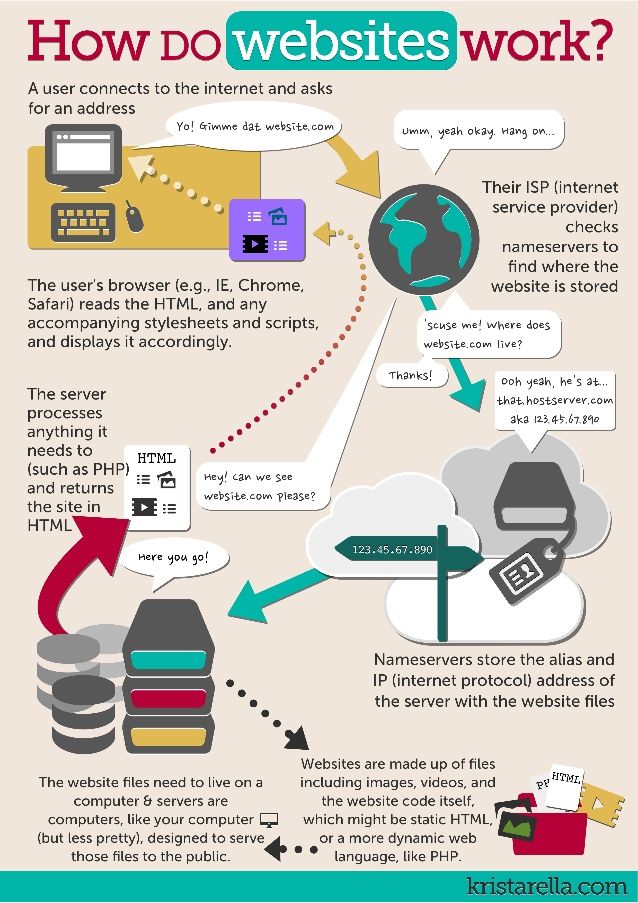 All optimization work was transferred to the Apache Hive project.
All optimization work was transferred to the Apache Hive project.
Hello friends, in today's lesson we are going to talk about a very sensitive topic. In particular, we will talk about privacy on Facebook. You will see the photos that we delete the account, they remain alive and well and that the Facebook servers for a long time, about 2 years. I see a lot of people posting dirty photos on Facebook that might at some point put them in a bad position. I know you probably thought that when the time comes to get or be more serious, I will delete the photos of this account and no one will know who you are, what photos you post or the situations created in some of your photos . All wrong! With a little mind and a simple browser, who can give in seconds your photo, even if you have sterso!
In this tutorial we want to draw a warning to all Facebook users:
- stop posting obscene photos
- don't post photos with jewelry boxes or a Swarovski crystal brooch made as a gift to your mother.
- never post information about days you won't be home or you'll be going on vacation
- don't post your address and phone number on Facebook, this is one of the biggest mistakes you can make.
- an employer can find out in a few seconds your whole life, history and the environment in which you move, he can know in a second your level of seriousness, devotion, before hiring you.
We hope that this tutorial will open your eyes and you will be more careful before making a public life, I invite you to watch the video tutorial
Remember that if you have suggestions, complaints or additions, feel free to write to comment box, de also if you met in the comment box the user has a problem and you can help him, feel free to do it, the only way we can make this place better is to see in the comment box!
The comment box is trying to get a little on the subject, so that other visitors can suggest a tutorial + comments related comments may be more support for user errors, or a desire to learn.
Before you ask a question, try to refer to the comments of the elders, in most cases your question has already been answered there.
Use more categories at the top of the site and the search engine on the right hand corner to quickly get to what you are interested in, we have over 500 tutorials that cover almost every genre of software, we get it, you just have to search for them and watch them.
Instructions for use videotutorial.ro
Search Engine.
If, for example, you have problems with Yahoo Messenger, you can enter in our search engine terms such as Yahoo, Mess, Messenger, ID mess, multimess messenger problems, messenger errors, etc., you will see that you will have a choice.
Categories.
If you use the category dropdown, they find the bar in the home categories: Office, Graphic Design, Hardware, Internet, Multimedia, Security, System, Storage, Backup, sub-categories and sub-sub-categorii are organized under these categories, this is more accurate filtration.