Extract all sorts of data from Facebook with our web crawling tools.
No bandwidth limits. Crawl and scrape as many web pages as necessary
Protect your web crawler against proxy failures, IP leaks, and CAPTCHAs
Achieve maximum scraping efficiency
Your first 1,000 requests are free of charge!
Create a free account and then apply from the dashboard.
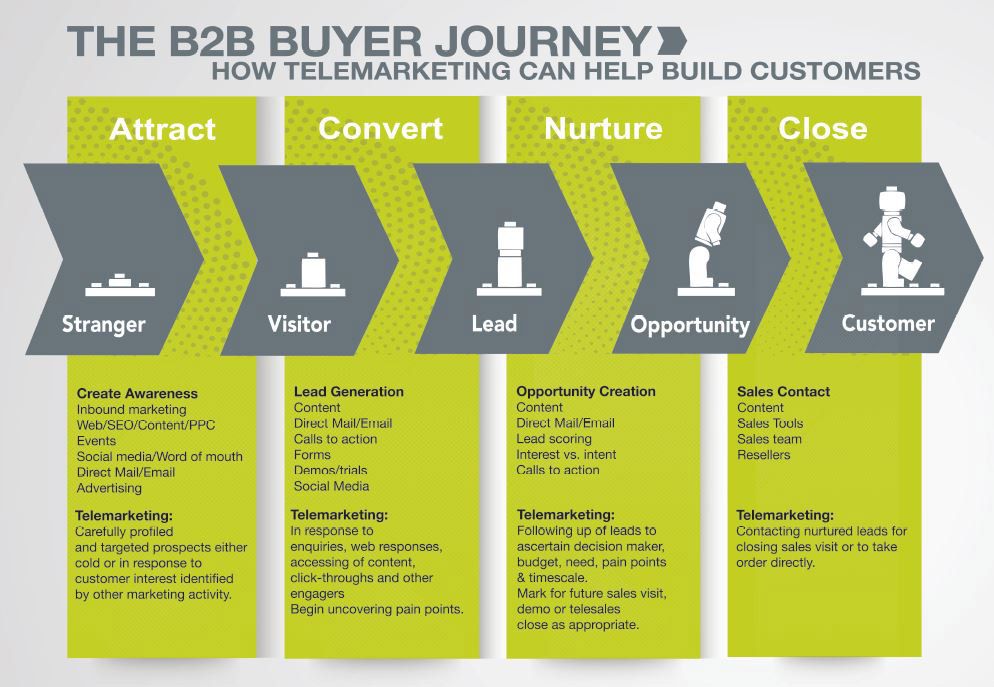
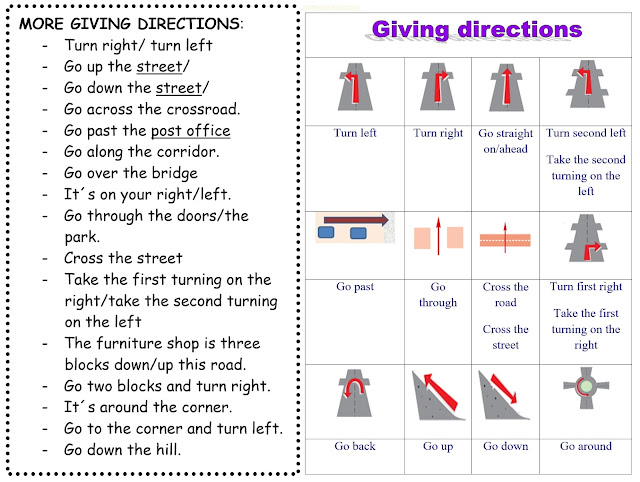
Facebook is currently the world’s biggest social media platform. With almost 3 billion monthly active users, there is no doubt that here, you will find a vast amount of data that can be useful for SEO monitoring, brand campaigns, or marketing plans.
However, retrieving Facebook data is no easy task and you will need proxies to avoid getting blocked and bypass CAPTCHAs. With the help of Crawlbase, you can easily overcome these issues by using our crawling and scraping products.
Scrape every Facebook page you want. You can crawl anything from news feeds, search results, to public groups. With an average response time between 4 to 10 seconds, you can ensure that your projects will stay efficient and only fresh data is acquired.
Need help contact us
Our APIs are built on top of thousands of residential and data center proxies worldwide combined with Artificial Intelligence so you can anonymously scrape various Facebook pages. Crawlbase can effortlessly avoid CAPTCHAs and has the best protection against blocked requests.
Get data for your projects without worrying about setting up proxies or infrastructure, so you can focus on what matters most- growing your business.
Need help contact us
For beginners and experts, for small and big projects, for casual users and developers. Our API is so easy to use you can start scraping Facebook in minutes.
Get your token now by signing up and try your first API call with just one simple cURL request:
Use our Crawling API to get the full HTML code and scrape any content that you want.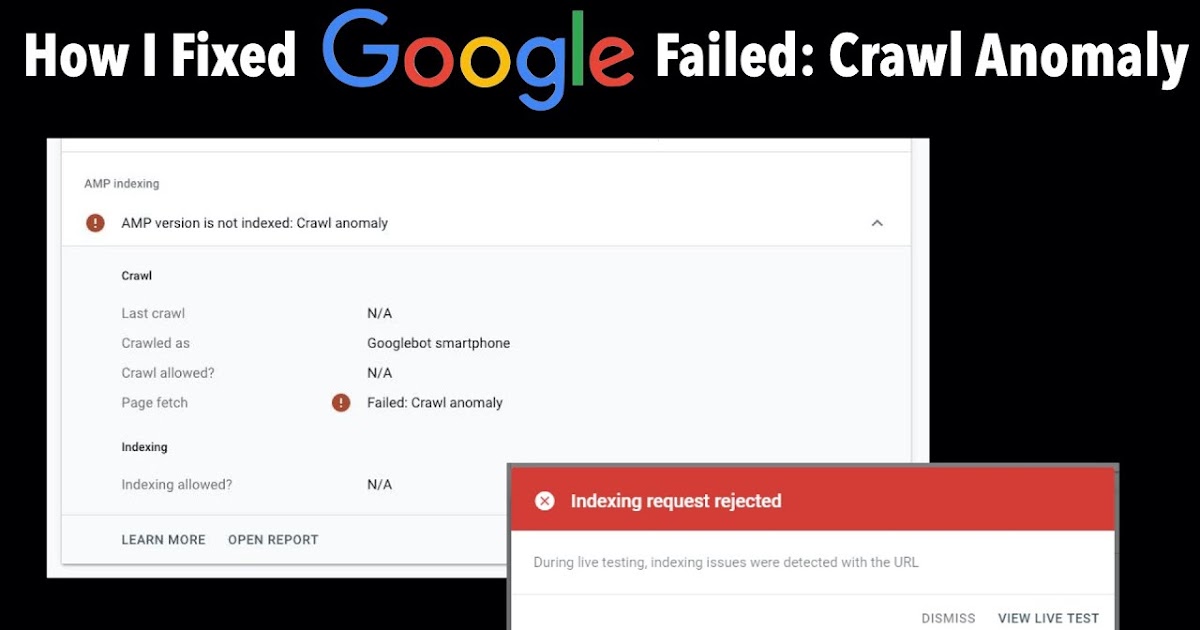
Take a screenshot of an entire Facebook page on any screen resolution if you wish to keep track of any changes easily with our Screenshot API.
Send your crawled pages straight to the cloud using the Crawlbase’s Cloud Storage.
For huge projects, you can use the Crawler with asynchronous callbacks to save cost, retries, and bandwidth.
Need help contact us
We are loved by thousands of individuals and companies around the world. Our goal is to provide the internet data freedom you deserve.
Your first 1,000 requests are free of charge,Sign up now
Pay-as-you-go pricing with no hidden fees.
It is your account and you decide when to stop, can be cancelled at any time.
You can check our FAQ section or ask question by clicking Contact us
Customers & Clients
Supporting all kinds of crawling projects
Create Free Account!
Create a free account and then apply from the dashboard.
Start crawling in minutes
Crawling Facebook is against Facebook’s policy unless you have express written permission. Following post is just meant for educational purposes. I do not encourage anyone to crawl Facebook.
There is tons of information publicly available on social networks, which, sometimes we even forget exists. In this tutorial we will learn how to get some of the publicly available information on Facebook platform, allowing us to perform exploratory data analysis. That includes (but not limited to) detecting a user’s sleep patterns, online activity patterns, social network graphs, chat history, and different associations in the data.
This post is divided into two sections:
Facebook keeps tons of information on us, which goes all the way back to when we first started to use the social network. You can download your own archive of this information if you want to see what Facebook knows and for getting insights from the data.
You can download your own archive of this information if you want to see what Facebook knows and for getting insights from the data.
Getting a copy of your personal Facebook data is very easy. Here’s how you can do that:
You can see all of your private and public information, your message threads, and a lot of other stuff in the downloaded file.
Facebook Graph API endpoints related to friends’ data were closed permanently because of changing privacy policy.
Getting friends’ data is not very straightforward anymore. In light of Facebook’s promises to protect their users data, Facebook has been continuously revising its Graph API, especially after the Cambridge Analytica debacle.
As a result, several Graph API endpoints have been closed completely including the endpoints related to friends’ information.
So no Graph API access means No access at all? Not exactly. We can still access the (publicly available) data using web browsers which means we can employ crawling tools to extract the information we need.
Let’s get straight to the job without further boring explanations!
We will be using the following tools/technologies for the purpose:
Install Virtual Environment (optional)
This step is optional but I would suggest you to create a python virtual environment for our project so that we don’t pollute global python environment. If you have Anaconda installed on your Ubuntu/Linux machine you can use conda command to create a python virtual environment:
$ conda create -n py35_fb python=3.5
$ source activate py35_fb # activate conda environment
There are few other ways to create a python virtual environment but explaining those is not the intention of this post.
Install Selenium
In our virtual environment, we can install selenium using pip:
pip install selenium==3.141.0
Download Chrome Driver
Because we want to run headless selenium (without GUI), we need to download Chrome Driver. Let’s download it, unzip, and place the chromedriver file from extracted folder in the working directory. We will be using this later for initializing headless version of selenium.
Please make sure that you download the compatible version of Chrome Driver for your Installed Chrome Browser.
We can find out the list of online friends either from Messenger’s web interface or from Facebook Mobile’s buddy page. In this tutorial, we will be using Facebook Mobile interface.
If you are new to crawling, I suggest you to read some introductory article about crawling like this one. Following is the image of how the buddy page looks like. The pictures and names are blurred for privacy reasons.
Figure 1: Facebook Mobile’s Buddy Page showing a list of Online FriendsLet’s see the HTML source of the page and find out where our required information exists in the page.
Following is the structure of the HTML source of the page. For the sake of understanding, I have excluded unnecessary content of the page.
<html>
<body>
...
<div>
...
<div>
...
<strong>
John Doe
</strong>
...
</div>
...
<div>
...
<div>
...
<strong>
Jane Doe
</strong>
...
</div>
...
</div>
...
</body>
</html>
We can see from the structure of the document that strong tag inside the div tag (with class ‘content’) contains the information we need.
Tip: You can use Chrome Dev Tools to analyze the HTML source of any page in Chrome.
That’s all the information we need for our purpose, now let’s get to the interesting stuff.
Let’s initialize selenium browser using the following piece of code:
Don’t forget to replace the value of chrome_driver_ex variable with correct path to chromedriver file. If above code is executed without errors, headless (without GUI) selenium browser should be opened successfully.
Note: Facebook blocks your account if there are several unsuccessful login attempts from unknown location.
Now we need to load the buddy list page and extract the required information. But before that, we need to login to our Facebook account. There are a few very important steps we need to take care of:
 It’s important that we first login into Facebook from the chrome browser in the machine we are using, so that Facebook trusts the location.
It’s important that we first login into Facebook from the chrome browser in the machine we are using, so that Facebook trusts the location.It’s of course possible to automate the authorization step required for login from unrecognized locations using selenium but that is more complicated and out of scope of this tutorial.
Next step is to analyze the structure of the buddy page to find out how we can fill the login form. I have already analyzed the structure of the login page for you, so we can skip to the code for login:
If above code works without errors, you can head into your working directory to see the logged_in.png image showing successful login.
But it’s very possible that you encounter some problems resulting in failed login. Let’s list down some of the possible causes.
 Seeing the logged_in.png should give you the idea of what is the problem.
Seeing the logged_in.png should give you the idea of what is the problem.Assuming that the login was successful, we can load the buddy list page and get a list of online friends. We can use XPath to get the required elements of the document using the following code:
That’s all it is. “names” is a list of available online friends at the time of crawling. We can load the page every half an hour (or more frequently) to get and store the list of online friends at a particular time and use the data later for the exploratory data analysis.
User’s online status is just a tiny bit of information compared to what’s available online and we can use the same crawling techniques to scrap other information. This article is also a reminder to us that how much of our information is available online.
This article is also a reminder to us that how much of our information is available online.
I hope this post was helpful for your work and research. If you have any questions, feel free to write a comment below.
Read related stories:
You can transfer data from Facebook in a semi-automatic mode to four platforms. The platform is a service to which you want to transfer your information from Facebook:
VKontakte, at the request of users, has added the ability to save materials from Instagram: vk.com/instagram_manager.To transfer pictures, just enter your username on Instagram or enter a link to your account. They will be included in the closed album "Instagram", but privacy can be changed at any time.
nine0003
In the future it will be possible to use the archive. Then the video will also be saved (in the "Video" section), as well as Reels (in the "Clips"). All materials will be visible only to you. So have time to download a file from Instagram with all the information.
Before moving on, let's determine what information is on the social network
Note. If you would like to download a copy of your Facebook information, check out the Download Your Information tool.
The View Your Info tool provides a summary of your Facebook profile that you can see in one place at any time. In the Your Information section, we've divided this information into categories to make it easier for you to find the information you're looking for. nine0003
In the Your Information section, we've divided this information into categories to make it easier for you to find the information you're looking for. nine0003
To check your Facebook information (eg recent activity), go to Your Facebook Information in Settings. Below is an instruction on how to go on your own, or you can use direct links and follow them, they are after the instructions.
To view your Facebook information:
icon in the top right corner of the Facebook window.
The following tools and resources are available in Your Facebook Info settings:
 In the activity log, you can see and manage the content you've shared (posts you've commented or liked, apps you've used, and content you've searched for) and manage it. Learn more about the activity log. nine0012
In the activity log, you can see and manage the content you've shared (posts you've commented or liked, apps you've used, and content you've searched for) and manage it. Learn more about the activity log. nine0012 You can select the platform to which you want to transfer a copy of your information in section Select platform function settings Transfer a copy of your information .
 If you delete or disable your account, the transfer may be interrupted.
If you delete or disable your account, the transfer may be interrupted. 
There are no social networks Vkontakte and Odnoklassniki in the list, so we download the information in JSON format. As of 02/26/2022, there is no possibility to import data to another social network, but it will appear in the very near future.
To download a copy of your data from Facebook, use the information download tool.
To download a copy of your Facebook information:
icon in the top right corner of the Facebook window.
2. Press Settings & Privacy and then Settings .
3. Select Your Facebook information on the left.
4. Next to Download information click View .
5. To add or remove data categories to the query, check or uncheck the boxes on the right.
6. Select other options such as:
7. Click Create file to confirm the download request.
Submitted download request will get status Pending and will appear in section Copies available of your download tool. It may take several days for us to prepare the files at your request.
You will be notified when materials are available for download.
To download a copy of the requested data:
To view information about the download request (such as format and expiration date), click More.
Note. To learn how to manage your data and privacy on Facebook, visit the Quick Privacy Settings page. To check recent activity on your Facebook account or view information about it, use the View My Info tool.
1. Log in to your Instagram account. Go to "Settings" then to the "Privacy and security" section, go to " Data download" and click "Request file". The "Download a copy of your information" screen appears.
2. Enter the email address to which to send the download link.
3. Select the JSON information file format.
4. Enter the password and click on the button "Request file ".
5. Within 48 hours (much faster) you will receive an email with subject Your information in Instagram , it contains a link to an archive file with messages, photos, comments, profile information.
6. Download the data, the link is only valid for 4 days after sending.
Yes. When you download a copy of your data on Facebook, you can specify which categories of information you are interested in, as well as set a date range to download information for a certain period. You can set such settings when requesting to download information. Learn more about the information contained in the downloads. nine0003
What is the difference between HTML and JSON copies of data?
When requesting a copy of your information from Facebook, you can choose the file format: HTML or JSON.
HTML. This is a Facebook data format that can be easily viewed. You will receive a ZIP archive. After opening it, extract the files from it. An HTML file called index. This file can be opened as a web page in a browser. The archive will contain folders with the files you requested, including images and videos. nine0003
nine0003
JSON. This is a machine-readable format with which you can transfer your data if you want to upload it to another service.
When requesting a copy of your information, you can also choose the quality of the media files (photos and videos). If you select a higher quality, the downloaded file will be larger and take up more disk space.
The Administrator can download a copy of the information from their Page. Copy includes:
To download a copy of information from your Page:
When the file is ready, you will receive an email or notification (depending on your privacy settings). In the email or notification, click Download Page and enter your password to continue. The link to your file is only valid for 4 days.
Photos and videos
You can only transfer copies of photos and videos that you have uploaded to Facebook and see on your profile.
Publications
You can only transfer copies of posts you create that you see on your profile, including:

 nine0012
nine0012  In such cases, only the content is migrated. nine0012
In such cases, only the content is migrated. nine0012  nine0012
nine0012 Notes
You can only transfer copies of the notes you create and see on your profile. Copies of some Facebook notes cannot be transferred. These include:
Events
For events you have created, you can transfer:
If you're an admin, editor, moderator, analyst, or advertiser and you've created an event for your Page, you can only transfer the title, time zone, and start and end times of the event. For other people's events you've been invited to, you can transfer:
To transfer information about another user's event to which you were invited, first respond to the invitation by selecting Attending or Interested in . You can't transfer information about events that you declined or didn't respond to.
in the top right corner of the Facebook window.
 nine0012
nine0012 Transfer a photo copy
Move a copy of the video
 You may need to re-enter your Facebook password. Complete the transfer by following the instructions on the screen. nine0012
You may need to re-enter your Facebook password. Complete the transfer by following the instructions on the screen. nine0012 Move a copy of publications
Transferring a copy of notes

Move a copy of events
There are several ways to view and manage your Facebook information in your Facebook settings:

Sources:
https://www.facebook.com/help/230304858213063/
https://www.facebook.com/help/212802592074644/
https://www.facebook.com/help/466076673571942/
https://www.facebook.com/help/1700142396915814/
RBC Trends explain how to download all important information from Dropbox, Apple Notes and Facebook services in the face of their possible blocking
In recent days, Roskomnadzor has partially restricted access to Facebook, and Twitter was experiencing crashes. Other services where Russians store valuable information were also under threat. RBC Trends tells you how to save your data when blocking popular applications. nine0003
Other services where Russians store valuable information were also under threat. RBC Trends tells you how to save your data when blocking popular applications. nine0003
WhatsApp chats can be configured to be copied daily and automatically saved to your smartphone. If the user decides to uninstall WhatsApp, they will need to manually back up their chats. To do this, open WhatsApp, click "More Options", select "Settings" → "Chats" → "Backup Chats" → "Backup". nine0003
The export function can be used for both individual and group chats. To do this, open the chat, click "More options" → "More" → "Export chat".
Find the option "Export chat" in the drop-down menu in the upper right corner of the chat
In this case, the user must choose whether he will export media files. After that, he will receive an email with an attachment in the form of a document in TXT format containing the history of correspondence.
After that, he will receive an email with an attachment in the form of a document in TXT format containing the history of correspondence.
To receive a copy of all materials, you must send a download request in JSON format. To do this, you will need to enter your Instagram account password. The user must go to their profile, click on the icon in the upper right corner, select "Your activities", click "Download information". Then you will need to enter the email address to which Instagram will send the download link and click "Request File".
Instagram asks for an email to send the archive
When saving data, the user can choose what content he wants to download, as well as set the date range for downloading. nine0003
To download all data from Facebook, you need:
 The download request will then have a status of "Pending" and will appear in the "Available Copies of Your Information Download Tool" section
The download request will then have a status of "Pending" and will appear in the "Available Copies of Your Information Download Tool" section .
Facebook allows you to select the format, quality and time range for saved files, as well as their categories
It may take up to several days for Facebook to prepare the archive. Then the user will receive a notification from the social network.
To download a copy of the requested data, you need:
User can choose HTML or JSON file format to download files.
The latter is more convenient for transferring data to another service. nine0003
To submit a request to upload an archive of tweets, the user needs to click the "More" icon in the navigation bar to go to the account settings. Then you need to select the item "Your account" in the menu, click "Upload an archive of your data", enter the password in the section "Upload an archive of your data" and click "Confirm".![]()
The user will then receive a code to the account's stored phone number or email address. After confirming your identity, you need to click the "Request data" button. Twitter will send an email or push notification when the download is complete if the app is installed on the smartphone. After that, in the settings in the "Download data" section, you can click the "Download data" button. The archive is uploaded in ZIP, HTML, JSON formats. It may take several days to prepare. nine0003
Upload Your Data Archive button in the Twitter account dashboard demographic information, advertisement information, and so on.
You can transfer files and folders from your Dropbox account to your computer. To do this, you need to sign in to your account on dropbox.com, hover over the file or folder you want to download, then click "..." (ellipsis) and select "Download". nine0003
Download a folder with photos from Dropbox
This way you can download folders up to 20 GB in size, the number of files in which does not exceed 10,000. All folders are downloaded as ZIP archive files.
All folders are downloaded as ZIP archive files.
Dropbox Paper docs must be converted to one of the following formats to download to PC: DOCX, MD, or PDF. To do this, click "..." (ellipsis) in the document, select "Export", select the file format to download and click "Download".
The DOCX format will only be compatible with Microsoft Word, not Google Docs or OpenOffice. nine0003
Most users sync their notes with iCloud accounts. To upload notes from iCloud on Mac, you need to:
Windows users must first install the iCloud app on their computer and then sync their notes with Outlook. In the iCloud app, you need to:
In the iCloud app, you need to:
Selecting notes to download in Backup Explorer (Photo: macroplant.com)
All iCloud notes will be available in the selected folder on the computer.
The export function can be found in the Board menu → More → Print and Export. The information is downloaded in JSON format. It is currently not possible to import the archive back to re-create a Trello board. nine0003
Export board from Trello
Trello Premium allows you to export all boards in your workspace in CSV and JSON formats. Also the user can include all their attachments as a ZIP file in their own format.